Data volatility is a significant challenge that organizations face when dealing with big data. The traditional Vs of big data - Volume, Velocity, and Variety, fail to capture the impact that volatility has on the success of big data projects. Volatility refers to data whose value fluctuates over time, making it challenging to identify, store, and process. Volatility demands discovery and discovery drives the long-term health of big data efforts.
In this blog post, we discuss the significance of volatility and how it impacts the overall success of big data projects. We explain how managing data volatility effectively can pave the way for a more adaptive data environment that unlocks the true potential of your volatile data.
To achieve this, organizations need to rethink their approach to data discovery. By empowering data stakeholders with development best practices and tooling, businesses can draw better business conclusions from their volatile data. We identify the key requirements for an effective data discovery strategy, including the need for AI-driven, open-source connectors, a code-first approach using established development best practices, and an efficient local testing solution.
The Big “Big Data” Problem
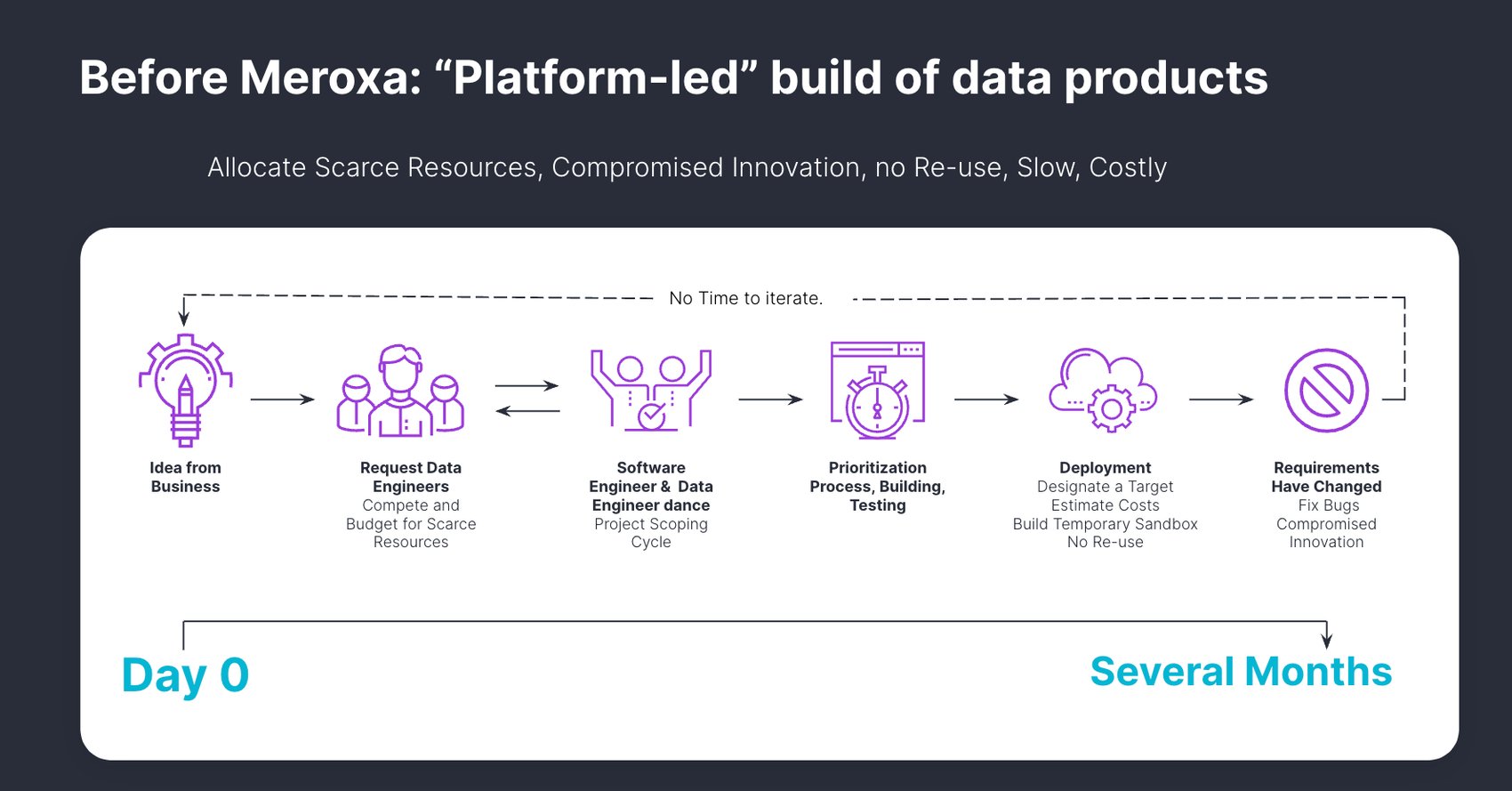
Big data efforts fail 85% of the time. In fact, it has been well documented that 70-80% of small data, data warehouses also failed. The reason for these high failure rates lies in their shared platform-led approach to optimization and neglect of discovery. That narrow focus hampered their ability to remain relevant and up-to-date. As a result, big data lakes turned into swamps, and small data warehouses lost their reliability.
Source: https://designingforanalytics.com/resources/failure-rates-for-analytics-bi-iot-and-big-data-projects-85-yikes/
The crux of the problem is that these efforts do not foster effective discovery processes driven by developers. Instead, they adopt a platform-led discovery approach that introduces significant delays and prevents developers from adequately supporting the discovery process. Consequently, these big data initiatives are unable to adapt and meet the evolving needs of the business.
The fact that big data is big is a challenge. A platform-led approach is very good at optimizing performance of known challenges using known data. However, big data solving known performance challenges is not why data lakes turn into swamps or why they continue to fail at 85%. They fail because they do not enable developer-led discovery to keep the data relevant and current to the needs of the business.
💡 For example, a popular ride-sharing company, managed over 100 petabytes of data, including trips, customer preferences, location details, and driver information. As the volume and velocity of data increased, the company had to build such a system that required significant investment in resources and infrastructure, highlighting the complexities of managing and leveraging massive amounts of data. Source: https://www.uber.com/en-CA/blog/uber-big-data-platform/
Why is Volatility the most important V?
Big data has traditionally been defined by the 3Vs. The 85% percent failure rate of Data Lake projects can be explained by the missing fourth V, which is volatility. Volatility refers to data whose value is indeterminate and changes quickly. Volatility considers changes in business objectives in real-time and how the value of data fluctuates depending on the current needs of the business.
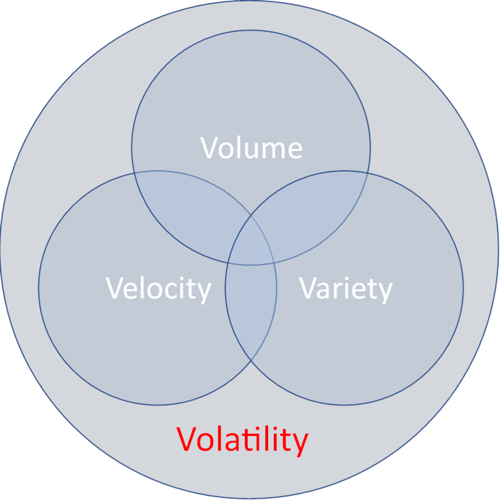
Volatility impacts the original 3Vs in the following ways:
- Volume: Volatility of data storage can result in swamps of unused data, and prevent discovery because potentially impactful data is left out.
- Velocity: Volatility of necessary latency of data can also lead to even greater volume and performance problems.
- Variety: Volatility in data types and needed connectors complicate identifying valuable data, integrating new sources, and maintaining effective data management systems.
In short, Volatility is the most important because your data stores can’t evolve to meet the needs of your business unless you properly handle volatility and its impact on discovery.
Rethinking the Approach to Volatile Data Discovery
Challenges such as technology complexity, and poorly defined business objectives, make data discovery a daunting task. Coupled with rapidly evolving business conditions and the inherent volatility of data, organizations often struggle to discover insights from their data. Although companies can execute data discovery projects, these efforts often come at a significant cost in terms of resources, system expertise, and long timelines. Even with such investments, businesses may still fail to achieve meaningful conclusions due to the constantly changing nature of business.
Addressing these challenges requires a new approach to data discovery that empowers data stakeholders with development best practices and tooling. By placing data stakeholders as the lead for discovery, they can draw better business conclusions from their volatile data.
Embracing an Effective Developer-led Discovery Strategy
The right tooling to embrace an effective data discovery strategy should offer the following:
- Put the data stakeholders closest to the data
- Remove the need for expertise in complex data technologies
- A fast, AI-driven, open-source, cross-platform approach for building connectors is vital.
- Connectors should be built quickly to support discovery.
- Open source connectors enable sharing not only within a single department or platform but also benefit the enterprise.
- A code-first approach using established development best practices:
- Leverages developers' existing expertise in specific programming languages.
- Enables developers to efficiently utilize familiar tools and frameworks.
- Encourages custom solutions, collaborations, and integrates into existing workflows
- An efficient and cost-effective local testing solution:
- Rapid iterations enable stakeholders to respond to changing business requirements.
- Allows for safe experiment with new data of uncertain value in an isolated environment without affecting the main system or incurring significant storage costs.
- The right tool should answer questions like, "What data should I collect now?" and "Why should I collect this data?" without being cost-prohibitive or resource intensive.
Addressing Data Volatility & Discovery with Meroxa
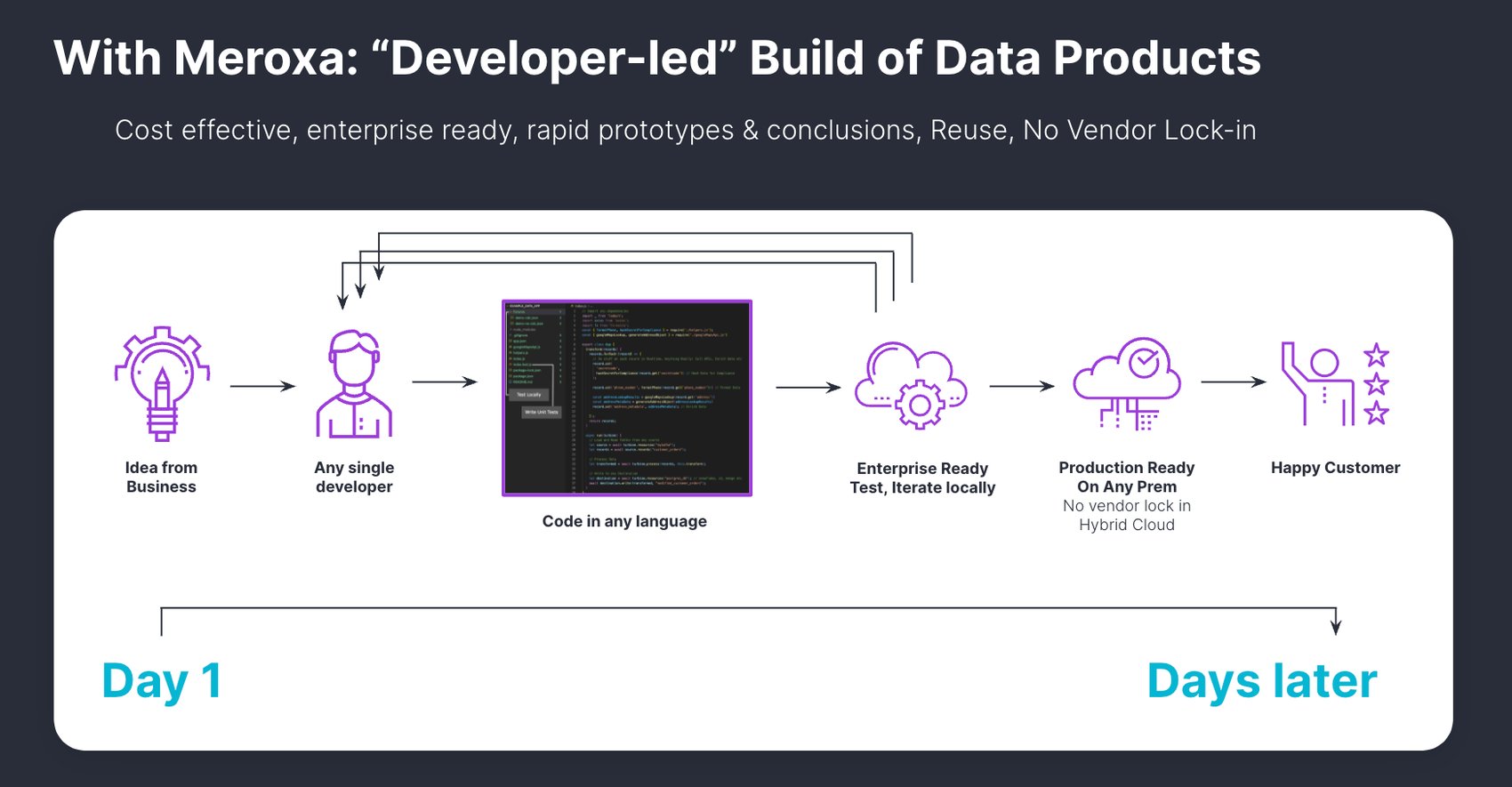
Having explored the significance of data volatility and the necessity for a developer-led approach, it becomes clear that organizations need a solution that caters to these requirements. Meroxa is that solution. Designed to address the challenges of data volatility, Meroxa empowers developers to take control of their data discovery.
Meroxa offers a vendor-neutral, developer-led, open-source, code-first approach that integrates well into any existing infrastructure.
Programming Language and Connector Neutral
Meroxa's programming language and connector neutral approach empowers developers to maintain optimal productivity. By providing connectors for a wide range of data stores, such as databases, cloud platforms, SaaS applications, APIs, data lakes, and messaging systems, Meroxa enables seamless integration and flexibility, catering to diverse needs in the ever-evolving technological landscape.
Meroxa addresses this issue by offering connectors for any data store, including databases, cloud platforms, SaaS apps, APIs, data lakes, and messaging systems.
Developer Led
In order to increase velocity and reduce time to value of new data products and initiatives, the Meroxa platform supports a developer-led, self-service approach. Once resources (such as databases and APIs) have been onboarded to the platform, they are made available for use via friendly names, with all unnecessary implementation details abstracted away.
This significantly reduces complexity by removing the need for deep knowledge of every resource type and improves flexibility as swapping resources is a matter of changing the reference. Developers can typically deploy fully functioning, production grade pipelines within hours.
Granular resource-specific security can be passed through the platform by applying security controls on the resource (taking advantage of the full fidelity of permissions and controls) and then registering associated credentials with the platform. Credentials are never displayed to the end user fully abstracting access.
Open Source
Meroxa embraces open-source principles to encourage collaboration and innovation within and beyond enterprises. Developers can build connectors faster with Meroxa's AI-driven method, and connectors are based on data stakeholder demands and actual use cases, rather than being dictated by platform providers' assumptions about what is needed.
Meroxa's open-source connectors are designed for rapid deployment, allowing developers to quickly and efficiently access a wide variety of data sources. By embracing the power of collaboration and developer-driven innovation, organizations can unlock the true potential of their data and drive innovation like never before.
Code-First
The Meroxa Turbine toolchain delivers a rich local development experience, allowing for a rapid/tight feedback loop. It builds on decades of software engineer processes and workflows, providing a familiar and robust developer experience. Developers build stream processing applications and pipelines using their favorite programming languages. They can leverage the wealth of existing libraries and packages in those languages.
One of the key features offered by Meroxa is local testing. Local testing creates a safe, isolated environment for developers to experiment with new data, test its value, and explore its potential uses without affecting the main system or incurring significant storage costs, empowering developers to innovate freely.
Organizations can also extend their software development processes and workflows to encapsulate data engineering with native support for Git, seamlessly integrating data operations into the established software development life cycle.
Conclusion
On a final note, reducing the time it takes to build data solutions is crucial for businesses to stay agile and competitive in today's fast-paced environment. Meroxa's developer-led approach empowers developers to take charge, streamlining the process and enabling quicker conclusions to evolving business needs. By shifting focus from platform-led optimization of data-driven projects to developer-led discovery, companies can enable their big data projects to evolve with the needs of the business. In essence, Meroxa's developer-led paradigm has the potential to guarantee success for your big data project in a world that has forever suffered with an 85% failure rate.
Don't let data volatility swamp your big data efforts. Don’t be part of the 85% failure rate of big data projects. To get in touch and see how Meroxa can help transform your data strategy, reach out to us by joining our community or by writing to info@meroxa.com.